Forskning beskriver hvordan man kan undersøke og manipulere den indre strukturen i store språkmodeller for å forstå hvordan de kommer fram til svar.
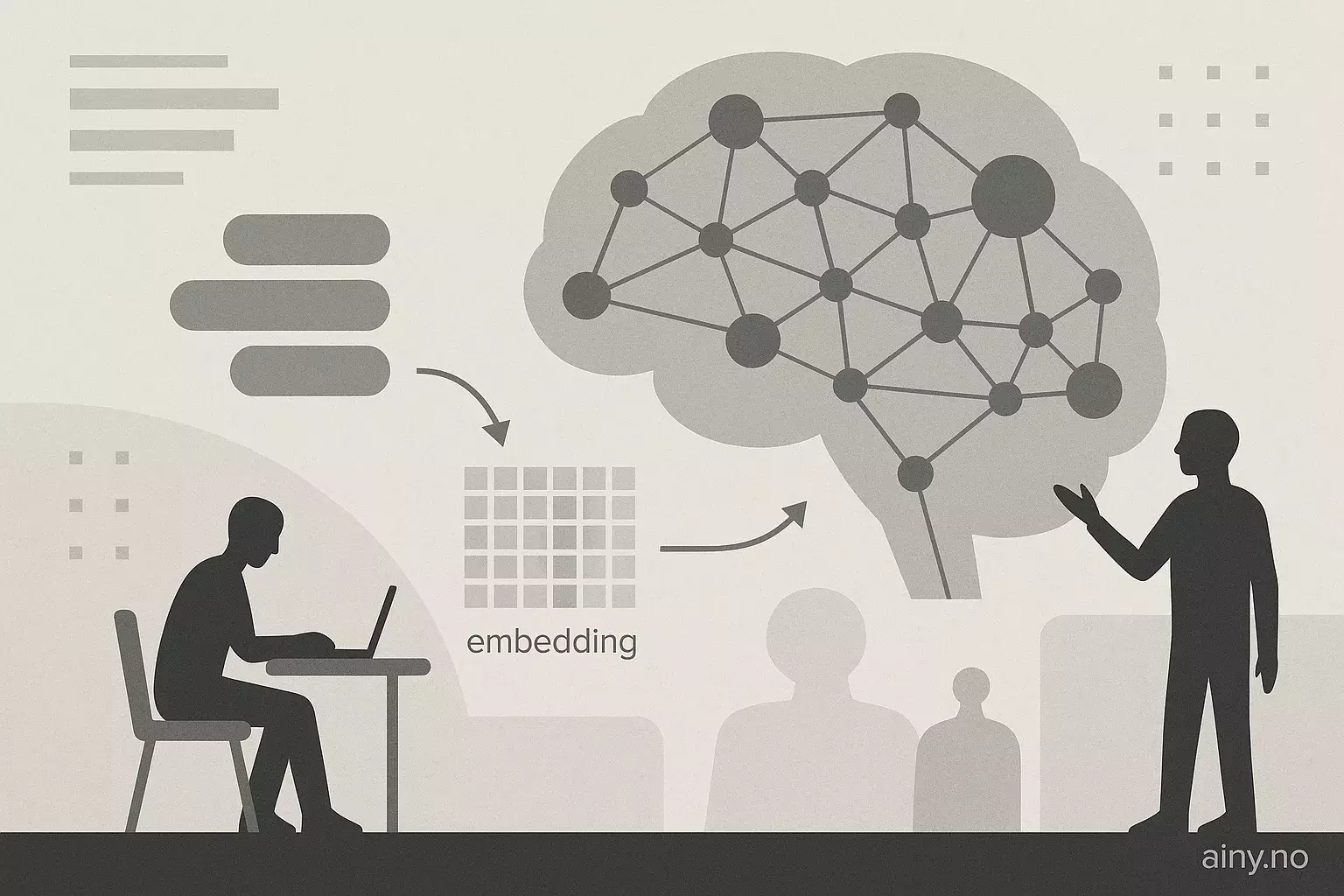
En stor språkmodell (LLM) består av flere deler: input settes sammen til tokener, disse får numeriske representasjoner i et innebygd vektorrom (embedding), og behandles videre gjennom mange transformerblokker. Hver blokk har oppmerksomhetsmekanismer (attention) og små nevrale nettverk (MLP) som endrer den skjulte tilstanden, kalt residual stream. Til slutt blir denne tilstanden omgjort tilbake til et ordvalg (unembedding). Mekanistisk interpretabilitet studerer disse mellomstadiene for å finne ut hva individuelle nevroner, oppmerksomhetshoder og deres spørringer, nøkler, verdier og vektninger gjør, og hvor kunnskap er lagret i modellen.
Slik innsikt er relevant for Norge fordi mekanistisk interpretabilitet kan bidra til å vurdere pålitelighet i tjenester som bruker kunstlig intelligens (KI). Dette er viktig for norske aktører og AI-nyheter.
Kilde: https://towardsdatascience.com/mechanistic-interpretability-peeking-inside-an-llm | Sammendraget er KI-generert med OpenAI API og kvalitetssikret av redaksjonen i Ainy.no